Plongée dans les coulisses de deux modèles d’IA qui voient vos images mieux que vous.
Vous avez des centaines de milliers d’images de vêtements. Rien d’autre. Pas un titre, pas une étiquette. Et pourtant, vous rêvez d’une interface où l’on tape : "montre-moi toutes les robes rouges avec un motif printanier", et bam, magie opérée.
Le Duo Choc : CLIP & BLIP
CLIP
OpenAIContrastive Language-Image Pre-training. C'est un modèle qui associe une image à du texte. Il transforme les visuels en vecteurs (traducteur vision/langage).
BLIP
SalesforceBootstrapped Language-Image Pretraining. Il génère directement des descriptions textuelles d'une image. Une phrase précise et fluide, presque humaine.
Petit scénario illustratif
Image : un homme marche dans une rue pavée, en trench beige, avec une valise.
- C CLIP : « Je transforme ça en vecteur. C'est proche de "gens marchant", "vêtements beiges", "scènes urbaines". »
- B BLIP : « a man walking down a cobbled street in a beige trench coat holding a suitcase. »
Et la concurrence dans tout ça ?
Extraction de caractéristiques visuelles.
Fusion texte, image, audio.
Compréhension du contexte multimodal.
Évolution pour tâches plus complexes.
Optimisé pour la qualité des descriptions.
Vision Transformer + GPT-2. Simple.
Assistants multimodaux.
Léger et open-source.
Mais ce qui distingue CLIP et BLIP, c’est leur complémentarité immédiate, leur finesse descriptive, et leur simplicité de déploiement.
Gimme gimme more...
BLIP peut être réglé comme une boîte à outils :
- max_length Augmente la longueur des descriptions (50+ pour la richesse).
- num_beams Recherche par faisceaux. 5 ou 10 pour plus de variations qualitatives.
- temperature, top_p, top_k Ajustent la créativité. Utile pour capter des nuances vestimentaires subtiles.
Derrière les modèles
Si CLIP et BLIP impressionnent, ils reposent sur des montagnes de données annotées à la main. Les coulisses sont moins reluisantes : sous-traitance dans des pays à faibles revenus (ex: Kenya, < 2$/h), filtrage de contenus choquants.
Ces pratiques soulèvent des questions éthiques majeures sur la valorisation de ce travail essentiel.
Mais pour qui ? Et pour quoi faire ?
Et pour le RAG (Retrieval-Augmented Generation) ?
Si CLIP et BLIP sont indépendants, leur complémentarité est précieuse pour bâtir un système RAG :
- CLIP retrouve les images proches (vectorisation).
- BLIP génère une description fine de l'image sélectionnée.
Ce duo est idéal pour créer un assistant visuel intelligent.
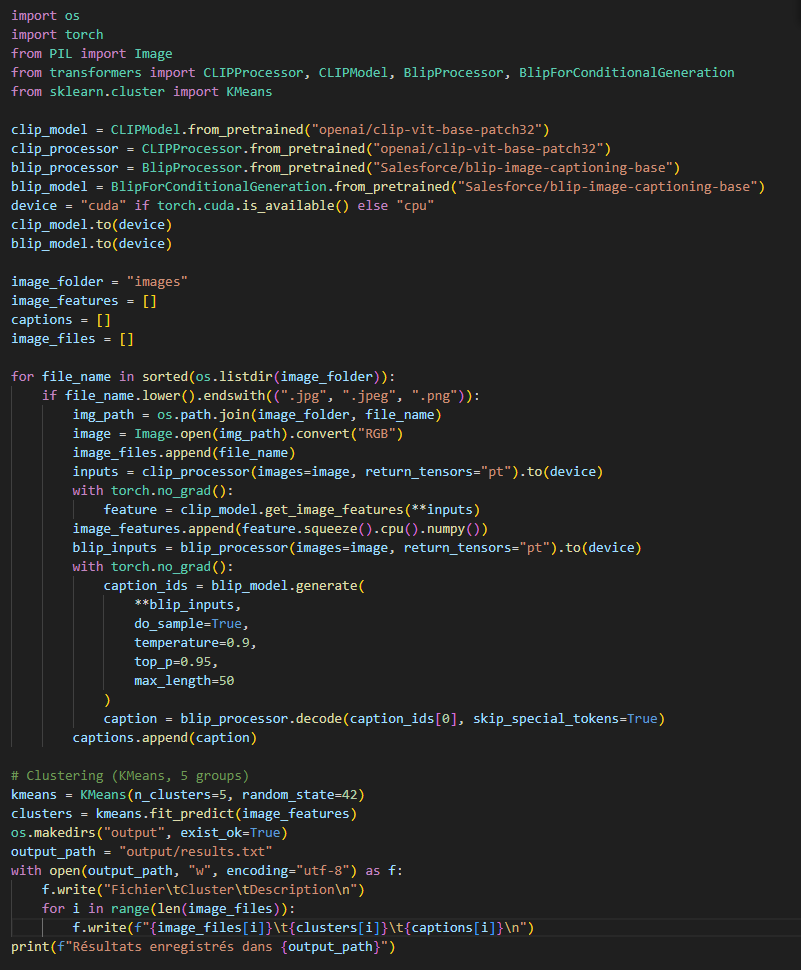
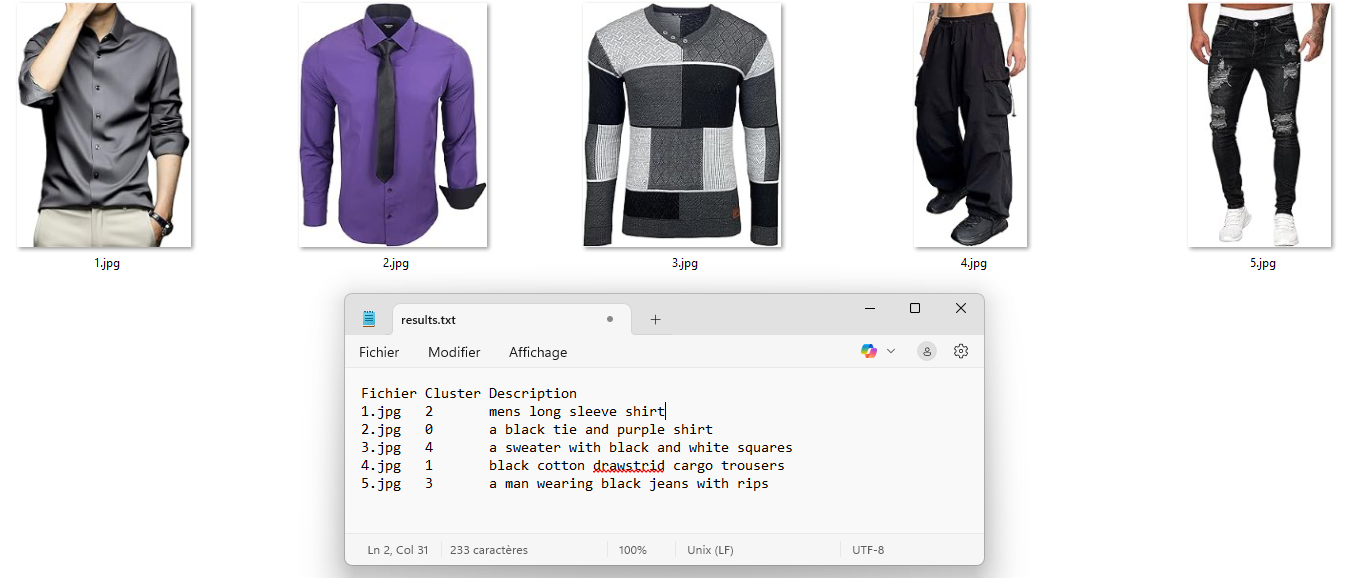
Un peu de code ! car on adore ça...
Script exécuté dans un environnement Docker, optimisé GPU. Bibliothèques : Transformers, PyTorch, scikit-learn.