La Clean Architecture revient souvent dans les discussions entre développeurs expérimentés… et très souvent aussi dans les entretiens d’embauche.
On en connaît le principe global, mais expliquer clairement ses couches, ses dépendances et son intérêt réel demande un peu plus de précision.
La Clean Architecture repose sur une idée simple : séparer strictement la logique métier des détails techniques. Le métier est au centre ; les technologies gravitent autour. On structure ainsi l’application en couches concentriques.
Entities
C’est le cœur métier, indépendant de tout. Pas de base de données, pas de framework, uniquement les règles essentielles.
Use Cases
Les règles applicatives. Elles orchestrent les entités et décrivent ce que le système doit faire.
Interface Adapters
Tout ce qui adapte les données au monde extérieur : contrôleurs, presenters, gateways…
Infrastructure
La périphérie. Frameworks, base de données, filesystem, providers externes.
Les dépendances sont dirigées vers le centre : le métier ne connaît rien de l’extérieur. Et c’est précisément ce qui rend l’approche stable. On peut remplacer un framework, migrer une base, changer l’UI : le domaine reste intact.
Ce que cette architecture impose, c’est de penser la logique métier avant les technologies. Pour un senior, cela force la discipline. Pour un recruteur, cela permet de distinguer un développeur qui organise son raisonnement d’un développeur qui organise seulement son code.
Principes incontournables Core Skills
Même si Clean Architecture structure les couches, plusieurs principes viennent renforcer la qualité interne du code.
SOLID
Cinq principes pour concevoir des modules fiables. SRP clarifie les responsabilités, OCP facilite les extensions, LSP garantit l’héritage, ISP évite les interfaces obèses, DIP protège le domaine.
DRY & KISS
DRY (Don't Repeat Yourself) évite les divergences. KISS (Keep It Simple, Stupid) rappelle qu'une solution lisible est toujours plus robuste qu'une implémentation complexe.
DDD (Domain-Driven Design)
Centrer le code sur le métier. Ubiquitous language, agrégats, invariants, événements… Une architecture claire ne vaut que si le domaine lui-même est bien compris et correctement modélisé.
CQRS : séparer lecture et écriture
L’architecture CQRS — Command Query Responsibility Segregation — découpe les opérations en deux modèles distincts :
- Command : modifier l’état (create, update, delete).
- Query : lire les données (get, list).
Pourquoi ? Parce que lecture et écriture ont souvent des contraintes différentes. La lecture demande rapidité, filtrage, optimisation. L’écriture demande cohérence et validation métier.
Avec CQRS, les deux évoluent indépendamment. Le modèle de lecture peut être dénormalisé, projeté, indexé. Le modèle d’écriture peut intégrer un vrai modèle métier riche.
Tests End-to-End : simuler l’utilisateur
Les tests E2E reproduisent le comportement d’un utilisateur réel : on vérifie que l’ensemble du système fonctionne, du front au back, jusqu’à la base.
// Scénario E-commerce type
1. User login
2. Search "Laptop"
3. Add to Cart
4. Checkout & Pay
-> Expect: "Order Confirmed" page
Les outils les plus utilisés : Cypress, Playwright, Selenium, Puppeteer. Playwright se distingue par sa performance et ses capacités d’analyse (réseau, console, traces).
Mise en pratique avec Laravel
Laravel fournit déjà une structure de base, mais rien n’empêche d’aller plus loin pour rapprocher le projet d’une Clean Architecture.
Une organisation possible
-
app/Domain
Cœur métier, entités, value objects. Aucun Eloquent ici.
-
app/Application
Use cases (CreateOrder, RegisterUser). Orchestration.
-
app/Infrastructure
Implémentations concrètes (Repositories Eloquent, Mailers).
-
app/Http
Interface adapters (Controllers, Middleware).
Dans un controller Laravel, on évite d’implémenter la logique métier directement. On injecte un use case.
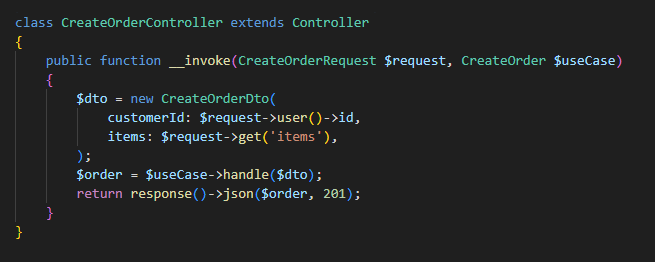
CQRS dans Laravel
On sépare les modèles riches du domaine (écriture) des modèles de lecture plus simples et optimisés.
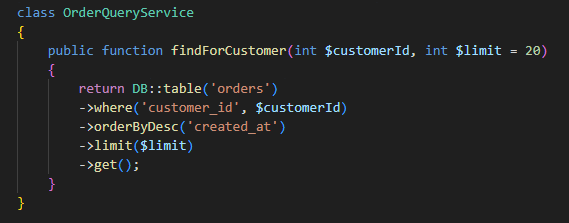
Optimiser les performances
La performance n’est jamais un bouton magique : c’est une méthodologie. Toute optimisation sérieuse commence par mesurer.
- 1. Diagnostic : APM, logs, métriques. Identifier les vrais goulots (DB, CPU, I/O).
- 2. Cache : Redis, HTTP cache, CDN. Avec une vraie stratégie de TTL.
- 3. Asynchrone : Déporter les traitements lourds (RabbitMQ, Kafka, SQS).
- 4. Scalabilité : Horizontal scaling, Kubernetes, gestion fine des ressources.
Les géants de la tech
Netflix
Pionnier des microservices après une panne majeure. Services autonomes et résilience extrême.
Uber
Architecture DOMA (Domain-Oriented). Plus de 1300 microservices organisés par métier.
Spotify
Organisation en "tribus" et "squads". 800+ microservices pour une autonomie totale des équipes.
Amazon
La règle des "Two-pizza teams". Petites équipes responsables de leur périmètre de bout en bout.
Sam Newman rappelle un principe fondamental : commencer simple. Les microservices — et par extension les architectures très découpées — doivent être une évolution, pas un point de départ.
